JSP Refactoring via Static Includes
Originally published: 2009-02-15
Last updated: 2015-04-27
In a perfect world, web applications are built using the MVC pattern, where business logic resides in one place, presentation logic in another, and there's a clear separation between the two. In the real world, web apps are usually built from massive, monolithic JSPs that have grown organically over a period of years. Even in applications built using an MVC framework, a real-world view may be enormous, composed of multiple independent sections based on the same model data.
This article describes a technique for refactoring such pages, similar to the Extract Method technique for program code. Like all true refactorings, the goal is to modularize the page without changing its functionality. Once the refactoring is complete, you can start thinking about functional changes that are enabled by the newly modular code.
Technique
Repeat the following steps until you don't see a point to doing so:
- Identify a cohesive block of JSP content and copy it into a new file (fragment).
- In the original file, replace the code with a static include that references the fragment.
- Verify that the page still works.
- Update the fragment, wrapping its entire content in a
<div>. - If you have scriptlets, insert opening and closing braces around them.
- Verify that the page still works.
- Check in.
One change from traditional refactoring is that I don't talk about unit tests. Partly, this is because it's notoriously difficult to write an effective automated test for user interface code. But a bigger reason is that a monolithic JSP is much like a monolithic chunk of program code: you often have to refactor just to make the code testable. So, testing is manual, and our goal is that a broken page will be immediately apparent: either it doesn't compile, or it doesn't look like it did before refactoring.
Now, to dive into the individual steps …
Identify a Cohesive Block of Code
Let's consider the product page for a
well-known eCommerce site — and before I continue, let me make clear that I do not work for this
company, and have no idea how their web pages are implemented. However, let's
assume that it's implemented as one big monolithic JSP.
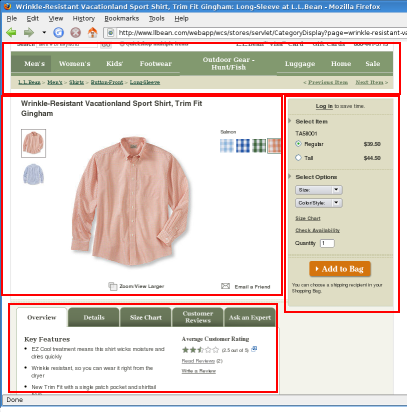
Visually, this page is divided into several large areas, which I've outlined: header, product image, add-to-cart box, tabbed descriptions, cross-sells, and footer (neither of which are shown here). These large chunks can be further subdivided: the product image box contains the product name, main image, swatch selector, alternate image selector, and a couple of text-based actions (zoom and email). So where to make the cut?
The answer has two parts. First: the cut should be made based on common dependencies. The areas that I've highlighted depend on a presumed product object, and not on each other. Therefore, the first factoring would be to split the code that generates these on-page blocks.
The second part of the answer is that refactoring is recursive: once you've extracted these large blocks, you can identify their internal dependencies and make additional divisions.
One thing to note: when I say “dependencies,” I'm talking about server-side code. If you go to the actual page that I've used as an example, you'll see that changing the swatch will update the add-to-cart drop-downs. That dependency, however, is confined to the rendered page. On the server, this should be no more than a shared dependency on ID constants.
Static Includes and JSP Fragments
Once you've identified a cohesive block of code, it's time to extract that
code into a separate file — a JSP fragment — and have the
original file include it. There are two ways that one JSP can include another:
dynamically, using the <jsp:include> directive, or
statically, using the <%@include> directive.
A dynamic include actually passes a new request to the application server: this request goes through the filter chain and is routed based on its URL. As a result, the included page is largely isolated from the including page: it's compiled separately, and has its own page context (but does share the request context).
A static include, by comparison, inserts the contents of the included file into the including file before compilation. The included file therefore has access to all variables and beans declared by the including page — because it is in fact part of the including page. Static includes have a bad reputation because of that level of access, and also because they make the compiled file larger (in extreme cases, pushing up against Java's method size limits). However, since our goal is to perform a refactoring, simply moving code from one file to another, a static include is the appropriate choice.
The code that we extract becomes a “JSP fragment,” also called
a “JSP segment.” This fragment does not, on its own, create a
valid HTML document: in the case of our refactorings, it will generally
create a single div. It may not even be compilable on
its own: refactored code often refers to variables and functions defined by
the including page.
As a result, you want to clearly identify these files as “not quite a
JSP”; one convention is to use the extension “.jspf”.
Some people also believe in putting them under the WEB-INF folder, so that they're not accessible via a URL. I see no good reason to
go to this extreme, since there's no way to discover their existence from
outside of the app-server. On the other hand, there's a decided
maintainability benefit to keeping refactored fragments together with their
including file.
Once we've extracted the major pieces of functionality into fragments, the main product page JSP will look something like the following (the use of a table for formatting is intentional; remember, this is legacy code!):
<%@page contentType="text/html"%>
<%@page pageEncoding="UTF-8"%>
<html>
<head>
<title>Product Page</title>
<link rel="StyleSheet" href="product.css" type="text/css">
<script src="product.js"></script>
</head>
<body>
<%-- common setup --%>
<table width="100%">
<tr>
<td> <%@ include file="prod_header.jspf" %>
<tr>
<td> <%@ include file="prod_image.jspf" %>
<%@ include file="prod_details.jspf" %>
<td> <%@ include file="prod_addToCart.jspf" %>
<tr>
<td> <%@ include file="prod_footer.jspf" %>
</table>
</body>
</html>
Encapsulate Extracted Code
The Extract Method refactoring, as its name indicates, creates a new method for the factored code. One of the under-appreciated benefits of this refactoring is that it cleans up the variable definitions in the original method: variables used only by the new method are moved to that method. An even more under-appreciated result is that this calls out hitherto unknown dependencies: if you move a variable into the extracted method, and it turns out that some other code used that variable, your compile fails.
You can get the same effect from your JSP fragments by creating a scriptlet block:
<% { %>
<%-- fragment code goes here --%>
<% } %>
The JSP compiler will insert these braces into the generated Java file, with the effect of turning the entire fragment into a Java code block. Variables declared outside the block remain visible to code within the block, but any variables declared within the block are invisible to code outside. This will quickly show any hidden dependencies: the page won't compile.
Encapsulate Extracted Markup
One of the hallmarks of legacy JSPs is their use of HTML tables to control
layout. Since you're refactoring, rather than restructuring, you shouldn't
replace these tables by a div-based layout at this time. However, there's no
reason not to wrap the extracted code in a div, since
doing so won't change its behavior. Give each div a unique
ID (I use the fragment name), and an optional class (I find this less useful,
but it may help once you do restructure the page).
<% { %>
<div id="fragment_wrapper">
<%-- fragment code goes here --%>
</div>
<% } %>
You'll node that I've put this div inside the braces added
in the previous step. The long-term goal is to eliminate the local variables
and scriptlets that necessitated those braces. So they remain the outermost
content in the file, easy to remove.
Check-in Early, Check-in Often
While “identify a cohesive block of code” sounds easy, it's often extremely difficult to do so in a large, monolithic JSP. Once you do identify a block, extract it, and verify that the page still works, it's time to check-in the changes. There are a couple of reasons to do this: first, of course, it keeps you from losing work due to a mistake (such as deleting code before creating a fragment from it).
Second, it lets you move on to other things. The goal of refactoring is to improve the codebase without changing behavior. It's an activity that can take place at any time, and over a long period of time — you don't need to refactor the entire page at once. Instead, you can refactor as needed: pulling out the cross-sell control, for example, while you're changing its layout. Or perhaps you have some time between projects, and want to improve the codebase as much as you can.
And third, it creates an environment in which you're not so worried about making mistakes, because you know that you can always revert to a working version. I think this fear is what prevents code cleanup: the possibility that you'll introduce a bug that isn't detected until weeks or months down the road. With constant checkins, you know that you can fix that bug in a matter of minutes: simply throw away all the changes that you've done since introducing it (although more likely is that you'll be able to look through the refactored code and quickly find the bug).
Lather, Rinse, Repeat
As I said above, the process is iterative; it's also recursive. Start by breaking out large chunks of code, and then examine them for smaller chunks. You will end up with a relatively large number of fragments, most containing a few dozen lines of code or less. True, this will cause the initial compile times to go up, as the compiler has to combine the fragments into one JSP. But JSPs are only compiled once, and they can be pre-compiled if you have runtime performance problems.
On the positive side, extensive factoring means that you break hidden dependencies, so that you can change one fragment without affecting any others. Plus, the modularization means that problems can be quickly isolated and fixed. And who knows, you might just find obsolete code — code that was able to hide in a thousand-line JSP, but can't hide in a 20-line fragment.
But the biggest benefit of extensive refactoring is that you can move on to …
Restructuring the Page
Once you've refactored, you can start thinking about restructuring: changing the actual page content. Perhaps you want to re-arrange the layout: it's a lot easier when you can re-arrange a few includes rather than moving large chunks of markup. Or perhaps you want to change the style of markup — table-based layouts are so 1999. Or, you can make some more dramatic changes …
Convert Fragment to Taglib
The end result of refactoring will be small units of code, containing markup and layout management for a specific part of the page, with all dependencies passed in from the caller. The same description could be applied to a JSP tag.
I hesitate to suggest that all JSP fragments should be converted to tags. True, doing so makes them easier to test and reuse, and reduces the size of the compiled JSP. On the negative side, a typical web application doesn't have a lot of reusable components, and burying markup inside a Java class doesn't make a lot of sense.
However, if by refactoring you can extract layout logic into a taglib, and reference that taglib from the refactored markup, you should clearly do so.
Convert Fragment to Dynamic include
One of the problems with static includes is that they increase the size of the compiled JSP. Since the JSP is compiled into a single method, in extreme cases you may even exceed Java's method size limit. Dynamic includes avoid this problem by managing the include as a completely independent page, compiled separately from the including page.
The problem with dynamic includes is that each include means a separate pass through the app-server, which increases runtime cost. This cost would become excessive if you converted a large number of static includes to dynamic. In addition to the cost of handling multiple requests, you could also find that you're doing a lot of repetitive data management, since the included file has no access to variables defined by the including file (although it does have access to request-scoped objects in the page context).
As such, dynamic includes make the most sense for high-level factorings, such as the first pass of the product page described above. When used for components that are shared across pages, such as headers and footers, dynamic includes can reduce the overall footprint of your application. And by forcing you to carefully control dependencies, they act as a bridge to …
Load page components via AJAX
The easiest way to reduce load on your server is to not process requests. Of course, taken to extremes that means you don't do any business either. However, there is a middle ground, in which you let caching take some of the load off your server. Depending on your site volume, the opportunity may be limited to common page components; on a large eCommerce site using a content delivery network, it could cover most of the page content.
Your ability to do this, however, is limited by the number of dependencies that your components have: basically, how much the component URL will have to change as the overall page URL changes. But if you've followed a path of refactoring to static fragments, then to dynamic fragments, you will have broken unnecessary dependencies, leading to simple URLs and cacheable page fragments.
Case Study: An eCommerce Product Page
As I said earlier, I don't work for L. L. Bean, and have no idea how their product page is implemented. I do, however, work for an eCommerce company, and last year one of our clients wanted some fairly extensive re-organization of their product page. Nothing to be added or removed, but almost every element changed in appearance and position.
Unfortunately, “the” product page was actually three different JSPs, each serving a different type of product. And these pages were most definitely in the “large and monolithic” category, averaging 1200 lines of mixed markup and scriptlets. Approximately 60% of each page was duplicated, inherited via copy-and-paste from a common ancestor.
The basic refactoring took slightly over two days, followed by markup restructuring. At the end of the project, the main pages were down to around 150 lines each. There were 35 fragments, totaling 2500 lines of code, and ranging from 20 to 300 lines each. The initial effort of refactoring was more than paid back in reduced time for restructuring the three pages to use a div-based layout with external stylesheet.
But the real benefit came in QA: the number of defects was far below average for a similar-size project, and generally involved styling and markup problems rather than logic. More important, we fixed a longstanding production bug because we were now able to see the bad code, without being distracted by everything around it.
Copyright © Keith D Gregory, all rights reserved